

Suite à des tests d’une feature d’import de données, j’ai pu améliorer de façon significative une fonction qui est appelée de très nombreuse fois.
L’application PHP en question utilise de la double-écriture car c’est une migration progressive d’un legacy.
Les données à importer pour la feature proviennent d’un fichier et, pour chaque ligne, le traitement va créer des entités qui doivent être répercutées sur le legacy via la double-écriture.
Voici un profil Blackfire lorsque je limite à 10k lignes :
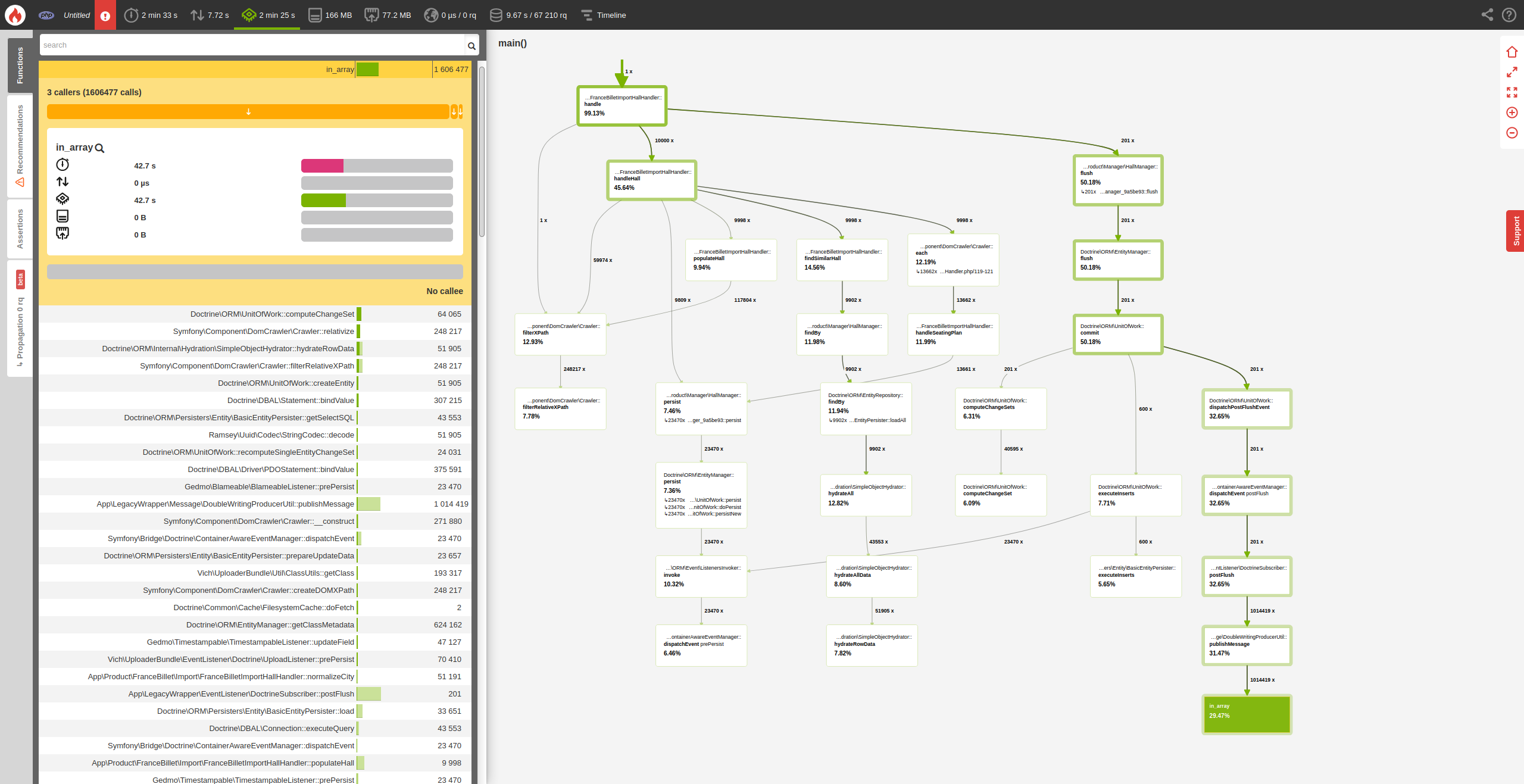
On peut voir que la fonction in_array() est appelée plus d’un million de fois dans un service de la double-écriture et prend ~29% du temps CPU à elle seule.
Si on jette un œil au code appelant :
public function publishMessage(?string $message, $queue = SyncLegacyDBConsumer::SYNC_QUEUE): void
{
if (null !== $message
&& !\in_array($message, $this->publishedMessages, true)
) {
$this->serviceLocator->get(sprintf('old_sound_rabbit_mq.%s_producer', $queue))->publish($message);
$this->publishedMessages[] = $message;
}
}
On voit que $this->publishedMessages est parcouru à chaque ajout d’un nouveau message pour éviter d’avoir des doublons et le tableau devient assez gros donc prend bien plus de temps pour le parcourir. On est donc en O(n).
L’idée est de transformer le tableau en dictionnaire en utilisant une clé unique pour chaque message : le message lui-même.
Ainsi, on a désormais un dictionnaire où on peut directement tenter d’accéder au message pour voir s’il est déjà inséré via isset() qui est très rapide en PHP. On est donc en O(1) en temps d’accès.
Le code devient le suivant :
public function publishMessage(?string $message, $queue = SyncLegacyDBConsumer::SYNC_QUEUE): void
{
if (null !== $message
&& !isset($this->publishedMessages[$message])
) {
$this->serviceLocator->get(sprintf('old_sound_rabbit_mq.%s_producer', $queue))->publish($message);
$this->publishedMessages[$message] = true;
}
}
Si on relance un profil blackfire, on a :
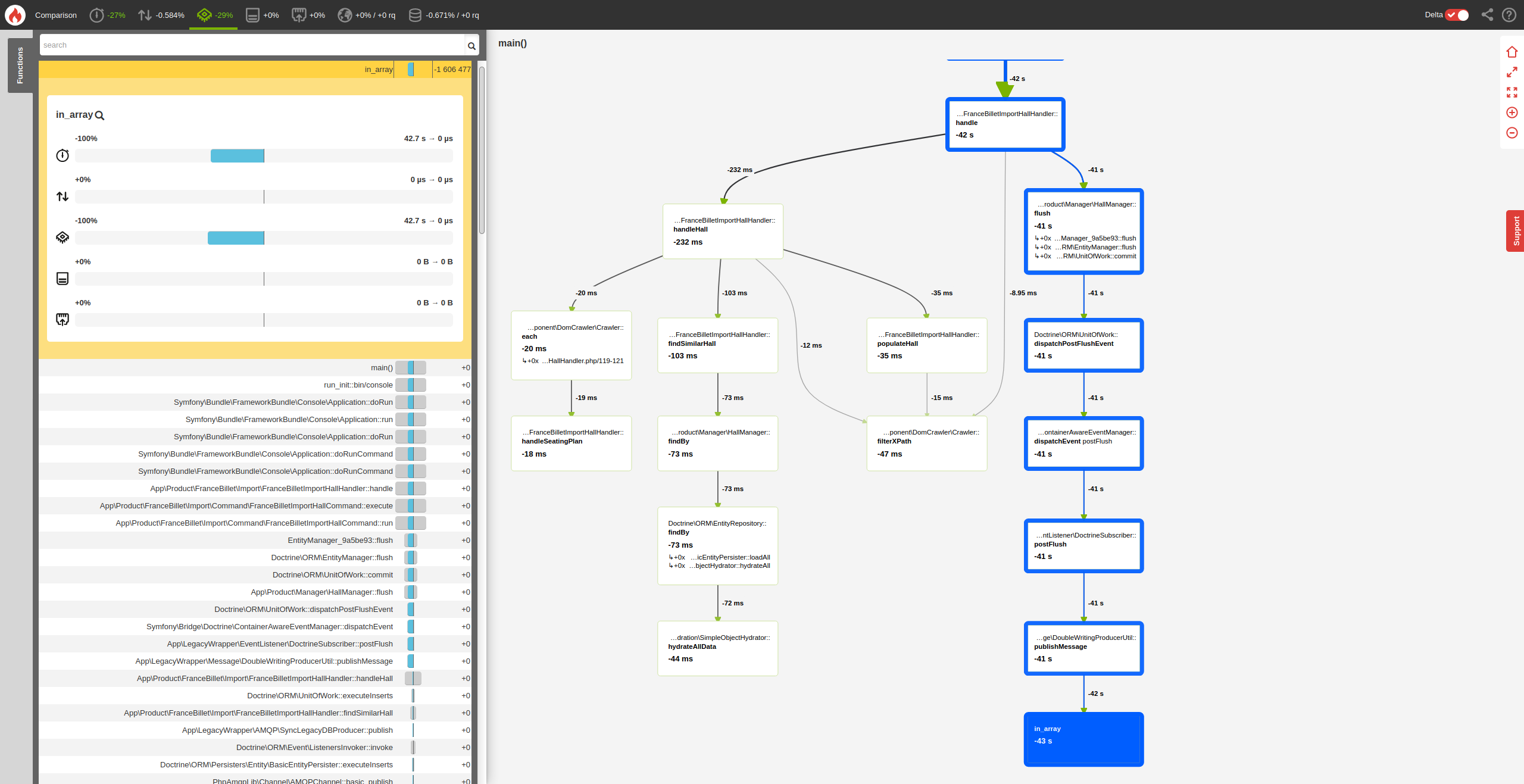
On a donc gagné, sur cet exemple, ~29% de temps CPU.
 Thomas Talbot
Thomas Talbot
